
Оглавление
1.1. Сотворение угла. 1 уровень
1.2. Сотворение цифр. 2 уровень
1.3. Сотворение цифровой матрицы. 3 уровень
1.4. Создание звуков речи. 4 уровень
1.5. Раскладка звуков по цифровой матрице. 5 уровень
2. Лексико-грамматическое развёртывание языка. 6 уровень
2.1. Корень и словообразование
2.3. Физиологическая функция алфавита
3. Развёртывание этнических языков. Этногенез. 7 уровень
1. Вначале было слово…
Принято считать, что язык есть средство общения людей. Это его главная функция, а все остальные функции1 в конечном счёте могут быть сведены к коммуникативной, то есть к функции общения.
Если вдуматься, общение, как таковое, вовсе не нуждается в таком сложном механизме, каким является человеческий язык. Достаточно примитивного языка, например, языка пчёл или муравьёв, благодаря которому они успешно существуют и организуют свои общества. Можно сослаться и на литературные примеры, хотя бы из Ильфа и Петрова. Всем словарным запасом и возможностями языка владеют и используют единицы, большинство обходится языком, близким к языку Эллочки-людоедки. Принципиальная возможность общения на примитивном языке подсказывает нам, что дело здесь в другом. Общение в том виде, как оно существует среди людей, нужно не только людям, но и, образно говоря, Творцу. Речь людей наделяет туннель реальности (umwelt) мерой, структурой и лексикой2: кирпичами, из которых складывается морфология3 космического «Интернета», устройства, управляющего миром, в том числе и людьми. Это и есть Язык, Слово, которое – вначале, и которое – у Бога и которое – Бог.

Невооруженным глазом видно, что разные способы письма являют собой систему, которая не может быть выведена из царапин на глине или зарубок на камне или дереве, как пытаются это сделать некоторые специалисты. На самом деле письменность построена на логико-символических основаниях, но настолько простых, что понять её не составляет труда даже для первоклассника.
Человеческий язык в целом един, как язык компьютера – ассемблер. Этнические языки, с которыми мы имеем дело, подобны языкам высокого уровня, по отношению к ассемблеру. Изучая структуры конкретных языков попробуем добраться и до ассемблера – единого языка мозга, Языка на котором говорит Бог. Рассмотрим последовательно логико-символические уровни письменности.
1 уровень – сотворение угла.
2 уровень – сотворение цифр.
3 уровень – сотворение цифровой матрицы.
4 уровень – создание звуков речи.
5 уровень – раскладка звуков по цифровой матрице.
6 уровень – лексико-грамматическое развёртывание языка.
7 уровень – развёртывание этнических языков. Этногенез.
1.1. Сотворение угла. 1 уровень
То, что точка – абсолют, было известно ещё в глубокой древности. И поэтому, вначале всей языковой конструкции лежит графическая точка. Арабы изобразили бы её в виде квадрата, но для нас её форма не имеет значения. Перемещая точку, получим линию. След движения точки есть линия. Далее из линии (угловым сканированием линии) получим угол.
Эти графические построения символичны. Точка символизирует абсолютное начало. Точка, перемещаясь прямолинейно, порождает линию. Любая линия кончается точкой, которой эта линия может быть и продолжена. То есть угол и линия – лишь разные ипостаси единого абсолюта. Отметим, что в Вавилоне абсолют и нуль, как символ вращения, обозначали кружком с точкой посредине.
Нетрудно сообразить, что угол есть лишь момент развёртывания точки в сферу. Поэтому точка, угол и сфера – разные моменты единого явления, единой сущности, которая есть пульсирующая сфера. Всё, что на свете есть колеблющегося, есть самая общая формула бытия, механизм восприятия которого построен на явлении резонанса.
Что касается угла, то это – символ человеческого интеллекта (не замороченного, светлого, пробудившегося) или самого человека, как его носителя.
1.2. Сотворение цифр. 2 уровень
Но самое любопытное в том, что из угла или (что тоже самое) единицы, конструируются цифры. Это делается простым сложением углов (единиц).
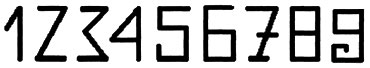
Нетрудно сосчитать и убедиться, что в каждой цифре столько графических углов (единиц), сколько реально она их содержит в числовом выражении. Эти угловатые цифры называют протоцифрами. Те арабские цифры, которыми мы пользуемся сейчас, отличаются скруглённостью углов. Так удобнее писать.
1.3. Сотворение цифровой матрицы. 3 уровень
Если мы каждую цифру увеличим на порядок дважды и выпишем единицы, десятки и сотни, включая и тысячу, так как это сделано ниже, получим числа брахми. Числа брахми складываются из трёх порядков: единиц, десятков и сотен.
Таблица 1. Числа брахми – русский (зеркальный) вариант

Таблица 2. Числа брахми – арабский вариант
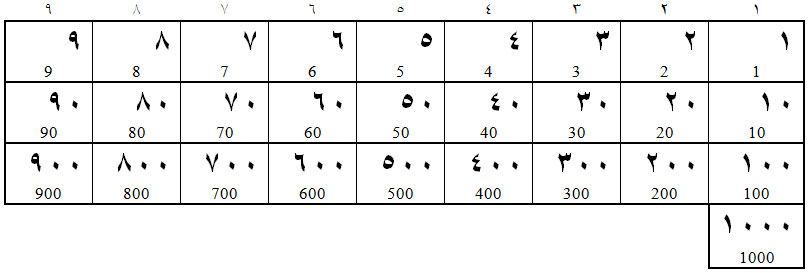
Каждый последующий порядок получен добавлением к исходной цифре нуля. Почему эти числа называются брахми, не известно. На самом деле – это матрица беременности. Судите сами. Данная таблица (цифровая матрица) состоит из двадцати восьми чисел, отражающих менструальный цикл (28 дней), умноженный на 10 (число акушерских месяцев беременности), что даёт срок беременности, равный 280 дням или десяти лунным месяцам, которые по продолжительности равны девяти солнечным месяцам. Брахми – это, вероятно, слегка искажённое русское слово бремя.
Таким образом, цифровой ряд тоже символичен. Цифры нумеруют месяцы беременности, исчисленные в солнечном календаре. Выше было сказано, что угол есть символ разума, тогда цифры символизируют помесячное развитие эмбриона в утробе матери. Срок исчислен в солнечном календаре, поэтому не случайно девятка рисует нам эмбрион, хотя из девяти углов можно было бы составить самые разные конфигурации.
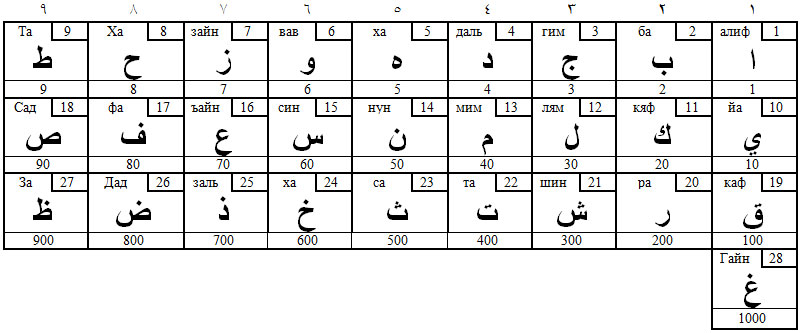
Арабские буквы происходят от арабских цифр и являют собой простые номера звуков. Это видно и невооружённым глазом. Например, первая буква Алиф имеет числовое значение – 1, пишется единицей ( ا), шестая буква Вав имеет числовое значение – 6 и обозначается шестёркой перевёрнутой – (و), девятая буква Та имеет числовое значение 9 и обозначается девяткой перевёрнутой – (ط), и так практически без исключений (кроме десятой буквы Йа – ي и варианта Алифа – ى ).
Между прочим, и в русском языке для образования чисел 10, 100, 1000, точнее их названий, применяется вращение. Берите первые две согласные из слов десять, сто, тысяча. Получите такой ряд ДС – СТ – ТС. Для выравнивания ряда оглушите первую Д (в русском языке оглушение и озвончение часто искажает корни). Что означает этот вращающийся корень? В арабском он означает девятку: ٩– тисъат. А почему же в русском им обозначается десятка? А потому, что первично он обозначал не число, а последний месяц беременности. В лунном календаре – это десятый месяц, в солнечном – девятый. Вот ведь какая штука получается. Арабы пользуются лунным календарём, а корни используют так, словно живут при солнечном. Мы же, наоборот, пользуемся солнечным календарем, а в глубине души у нас – лунный.
Невольно вспоминается обмен десятой буквой между арабским алфавитом и кириллицей. Кстати, синонимичность девяти и десяти в скрытом виде обыгрывается в русских сказках: в тридевятом царстве, в тридесятом государстве. Здесь девять значит то же, что десять.
Если внимательно присмотреться к этим словам, обнаружится, что они отличаются друг от друга только одной буквой. В середине девяти стоит В, в середине десяти стоит С. Кажется, что В ни при каких обстоятельствах не переходит в С. И в самом деле в звуковом отношении В совсем не похожа на С. Однако в арабском алфавите В обозначается шестёркой и означает шесть, тогда как С означает 60, а по начертанию С являет собой зеркальное отражение арабского Вава (русской запятой – و). Если обратить внимание на то, что и первая буква этих слов д является зеркальным отражением девятки, то становится ясным, что в русском слове «девять» замаскировано превращение шестёрки в девятку. В арабском языке эта идея отражается во вращении корня тисъ "девять" – ситт "шесть". Теперь Вы догадались, откуда у китайцев символ инь-янь?
1.4. Создание звуков речи. 4 уровень
Итак, цифровая матрица (таблица), как было сказано выше, состоит из двадцати восьми чисел, называемых числами брахми, числами беременности, отражающими лунный месяц. Каждая клетка этой таблицы соотносится с одним из 28 дней лунного месяца, а если считать её отдельную клеточку равной 10 дням, то всю её можно считать развёрткой срока беременности, равного 280 дням или десяти лунным месяцам, которые по продолжительности равны девяти солнечным месяцам.
С другой стороны, числа данной таблицы строго соответствуют числовым значениям букв арабского алфавита, число которых равно 28. При том, что каждая буква точно соответствует одному из 28 согласных звуков арабского языка.
Числа брахми складываются из трёх порядков: единиц, десятков и сотен. Каждый последующий порядок получен добавлением к исходной цифре нуля. Если же, вместо приписывания нуля (символа вращения или символа угла) вращать саму цифру, получим начертания арабских букв. Ниже помещены первые девять арабских букв (справа налево): А, Б, Г, Д, X, В, 3, X, Т в сравнении с арабскими цифрами. Во всех буквах до сих пор легко узнаются цифры, пожалуй, кроме пятёрки. Впрочем, арабы пишут пятёрку именно так, кружком.
Таблица 3. Арабские буквы, полученные вращением цифр

Если цифрой считать число, выраженное одним знаком, то в матрице мы имеем пока 28 цифр, которые станут буквами после размещения 28 арабских согласных звуков по клеткам матрицы.
Вывод: арабские буквы есть простые номера звуков.
Вопрос «в каком порядке размещены звуки в цифровой матрице?» должен быть предварён другим: «как получены 28 звуков?» Обратите внимание на их количество. Филологи всерьёз считают, что звуки речи возникли из диких воплей обезьян. Вряд ли из диких воплей обезьян можно получить именно 28 согласных, ровно столько, сколько нужно для заполнения цифровой матрицы. Итак, как же получены эти 28 согласных звуков?
В современном арабском языке есть четыре особых звука. Их называют эмфатическими, хотя правильнее было бы называть их двуфокусными. При произнесении этих звуков струя воздуха, продвигаясь по речевому тракту, встречает на своём пути препятствие в двух местах. Одно – там, где это происходит при произнесении русских звуков Т, Д, С, 3, т.е. в передней части речевого аппарата. Это передний фокус артикуляции. Другое – в задней части речевого аппарата, у корня языка, в гортани. Это задний фокус артикуляции. Так что при произнесении этих звуков, в отличие от всех остальных, на пути воздушной струи образуется преграда в двух местах, а не в одном, как это имеет место обычно.
Таким образом, при произнесении этих звуков используется передний фокус артикуляции и задний. Это так называемые эмфатические: (Т#) (Д#) (С#) (3#). Если за исходную четвёрку принять двуфокусные, то остальные группы согласных предстают как производные. Они получаются разделением фокусов артикуляции и перемещением каждого фокуса по речевому тракту вперёд, если мы снимем задний фокус артикуляции, останутся четыре обыкновенных звука (Т), (Д), (С), (3). Это вторая четвёрка звуков.
Кроме того, в арабском есть ещё одна четвёрка – четыре губных: (Б), (М), (В – произносится как английское W), (Ф). Препятствие для воздушной струи при их произнесении создаётся губами.
Если мы выделили три бесспорные группы согласных, в каждой из которых по четыре звука, то ясно, что и остальные шестнадцать делятся на четвёрки. Здесь важно обратить внимание вот на что. Все четвёрки согласных получены из исходной двуфокусной четвёрки путём разделения фокусов и троекратного перемещения каждого из них вперёд по речевому тракту. Так получаются семь четвёрок согласных. Все четвёрки отличаются друг от друга местом артикуляции, причём эти места располагаются в речевой полости таким образом, что в точности копируют структуру карточной колоды, как она изображена ниже.
Рисунок 1. Карточная колода

В чём сходство между арабскими согласными и картами?
Во-первых, как и карты, звуки речи разбиты на четвёрки.
Во-вторых, как и карты, звуки имеют старшую четвёрку, воплощающую в себе как бы два центра. В картах – это Туз. Его двуфокусность очевидна. Он является старшим среди картинок, следуя по старшинству выше короля. Он же является и старшей цифирью, поскольку, имея 11 очков, следует после десятки. В Тузе сосредоточены два центра иерархии, концы двух линий. Один – цифирный, другой – картиночный. И в этом смысле карточная колода, пусть и в замаскированном виде, построена по образцу угла, или, что то же самое, в вершине угла две точки (концы двух линий) совпадают в одной,а в колоде они несколько раздвоены, хотя и совмещены в Тузе. В звуковом ряду тузу соответствует четвёрка эмфатических, как мы сказали – четвёрка двуфокусных. Все остальные четвёрки образуются перемещением одного из фокусов артикуляции (заднего или переднего) вперёд, по ходу воздушной струи. Так что и арабские звуковые четвёрки, как и карты, построены по образу угла.
Одна линия иерархии соответствует карточной цифири: губные (ب, و, م,ف, – Б, В, М, Ф), шипяще-шепелявые (ج,ش,ث, ذ, – З, С, Ш, Ж (дж или г) ), переднеязычные ( د, ز, س, ت, – Д, 3, С, Т). Фокус артикуляции последних совпадает с передним фокусом артикуляции эмфатических.
Губные звуки (6) – Шипящие – шепелявые звуки (7) – Переднеязычные звуки (8).
Вторая линия иерархии соответствует картинкам: сонорные (ي,ل, ن, ر, – Й, Л, Н, Р), заднеязычные (ا, ك, ق, غ, – Хамза, Каф, Кяф, Гайн); гортанные (ع, ه, ح, خ, – Ъайн, и три разных X: – Х5, Х8 и Х600, где в индексе обозначено место звука в цифровой матрице или (что то же самое) его числовое значение).
Сонорные звуки (валеты) – Заднеязычные звуки (дамы) – Гортанные звуки (короли).
Таким образом, раскладка согласных звуков в полости рта такова, что последовательное перемещение каждого из фокусов артикуляции по речевому тракту как бы образует две линии, сходящиеся в группе эмфатических (двуфокусных).
В-третьих, звуковые группы, как и карты, внешне вытянуты в одну линию, за которой скрывается угловая структура.
Структуру звуковых групп от карточной колоды различает количество групп и в целом количество карт. Но ведь карточные колоды бывают разных объёмов, почему бы не быть и колоде в 28 карт? Причём, "звуковой туз" в таком случае будет иметь не 11 очков, а 9. При этом "звуковая колода" примет следующий вид.
Рисунок 2. Звуковая колода
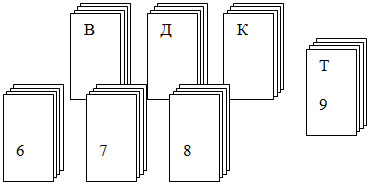
Как бы там ни было, звуковые группы настолько точно копируют карточную структуру, что нет проблемы дать каждой группе согласных карточное соответствие.
- Эмфатические соответствуют тузу, гортанные – королю, заднеязычные – даме, сонорные – валету. Это "вельможная" линия иерархии. Она располагается в задней части речевого тракта.
- Переднеязычные соответствуют восьмёрке, шипящие – семёрке, губные – шестёрке. Эти три группы согласных находятся в передней части речевого тракта.
Вывод: структура согласных копирует карточную структуру. Согласитесь, что получить все эти структуры из обезьяньих рыков, более чем невозможная вещь.
1.5. Раскладка звуков по цифровой матрице. 5 уровень
Поскольку в речевом аппарате у нас "звуковые карты", они, как пасьянс, раскладываются по клеткам цифровой матрицы. Четвёрками.
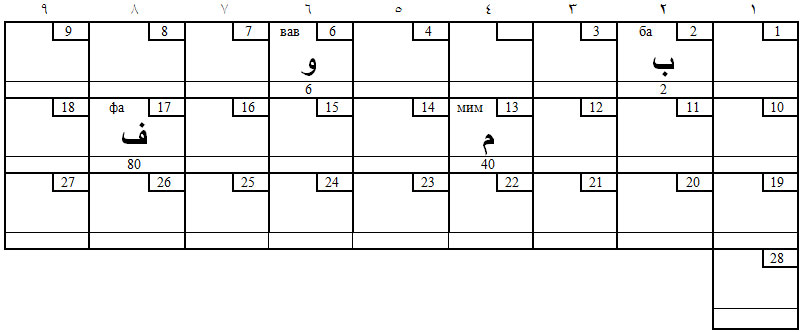
На первой – раскладка эмфатических (9, 90, 900, 800), на второй – губных (2, 40, 6, 80). Этих двух четвёрок достаточно, чтобы понять принцип: звуки раскладываются шахматным конём (или единицей) и ходами шахматного коня.
Таблица 4. Эмфатические звуки (туз)
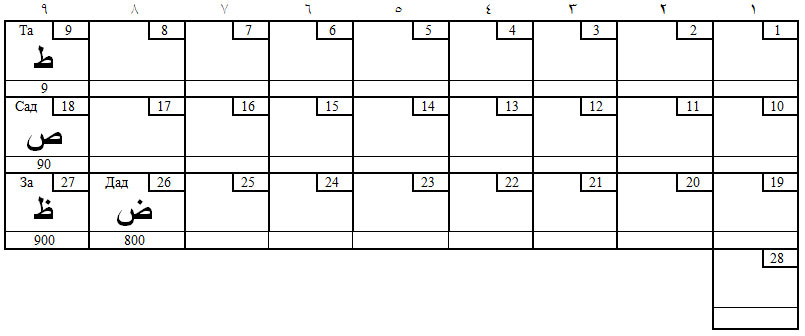
Таблица 5. Губные звуки (шестёрки)
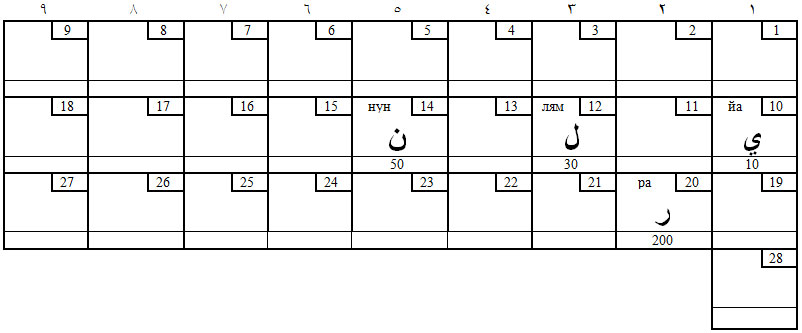
А вот на следующем рисунке группы выложены ходом пешки (со взятием фигуры). На первом – заднеязычные (1000, 100, 20, 1). На втором – сонорные (50, 30, 200, 10). Первый ход – типа е2-еЗ, второй – е2-е4, первая пешка бьёт вначале налево, потом – направо, вторая – наоборот, вначале – направо, потом – налево.
Обратим внимание на то, что шахматным конём переносится в матрицу главная группа согласных, т.е. тузовая четвёрка, и группа, соответствующая цифирной карте, в данном случае шестёрке. Что касается хода пешки, то он используется для групп, которые соответствуют картам-картинкам, т.е. карточной знати. Получается, что звуки речи при переходе в цифровую матрицу как бы меняются ролями. Вельможи во главе с королём обезличиваются, становятся пешками, а цифирь, подобно Тузу, въезжает в матрицу на коне. Точно как в Евангелии: бедные попадают в рай, а богатые вельможи – в ад. Туз, понятно, и в Африке – Туз.
Таблица 6. Заднеязычные звуки (Д)
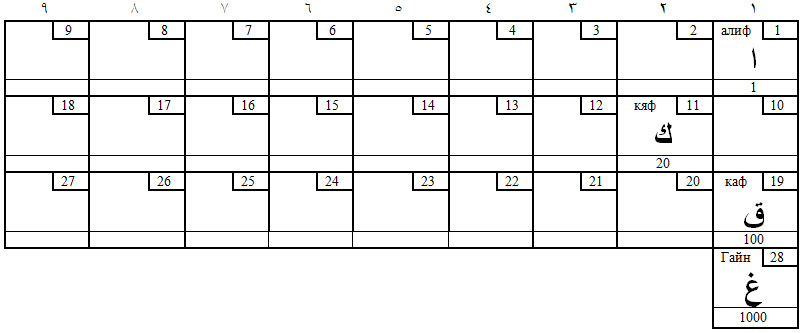
Таблица 7. Сонорные звуки (В)
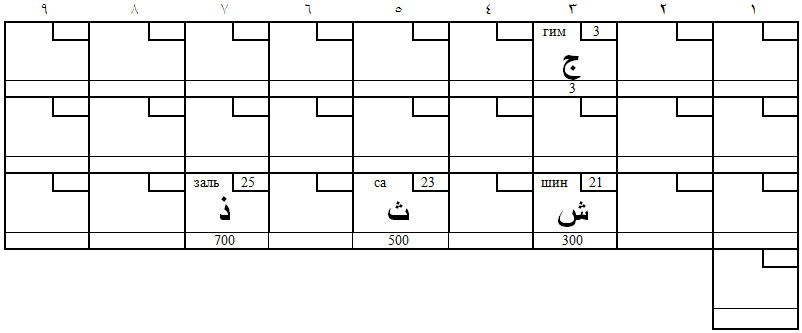
Вот ещё одна раскладка. На этот раз речь идёт о группе шипяще-шепелявых, соответствующей карточной семёрке. Тоже конём, буквой Г, только вдвойне увеличенной.
Таблица 8. Шипящие – шепелявые звуки (семёрки)
У нас остались ещё две раскладки: "звуковая восьмёрка" и "звуковой король". Эти "звуковые карты", каждая в своей линии иерархии, стоят непосредственно перед Тузом, который символизирует верховное божество, коль скоро и на этом свете, и на том он не меняет свою ипостась. Так что же происходит с теми, кто пред Богом? Пред Богом все равны. Посмотрите на раскладки этих четвёрок.
Здесь каждая из них совершена смешанным ходом, конно-пешечным; рабы и знать сравнялись, как им и положено, когда они пред Богом.
Таблица 9. Переднеязычные звуки (8)
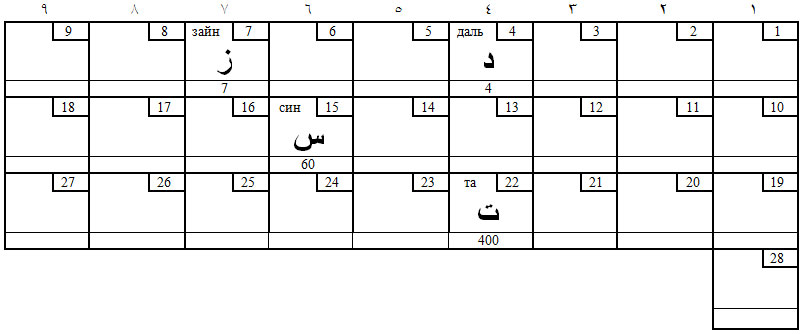
Таблица 10. Гортанные звуки (К)
Ход в первой матрице: пешка бьёт с 7 (буква 3 – ز) на 60 (С – س) и затем, превратившись в коня (пешка иногда имеет возможность стать конём в игре), стоит перед выбором: сделать ход на 4 (Д – د) или на 400 (Т – ت). Такова раскладка переднеязычных.
Ход во второй матрице: пешка бьёт с 8 (X– ح) на 70 (Ъайн – ع) и, превратившись в коня, делает два последовательных хода: на 5 (X– ه) и затем на 600 (X– خ). Такова раскладка гортанных.
Итак, все 28 согласных нашли свои места в цифровой матрице. Цифры, встретившись со звуками по изложенной выше системе, превратились в буквы и образовали последовательность, которая, хотя и в искажённом виде, сохранилась во всех алфавитных системах письма: К, Л, М, Н, О, П...
Некоторые алфавиты сократились, например, в еврейском – 22 буквы, некоторые буквы пустые, сохраняются только для того, чтобы в матрице не образовались лакуны. Так, Т9 и Т400 иврита в звуковом отношении уже не различаются из-за потери заднего фокуса артикуляции. Другие алфавиты разрослись до того, что не всем буквам хватило места в матрице, из-за чего некоторые буквы остались без номеров, как в нашей кириллице. Но порядок следования букв местами сохранился, что указывает на первоисточник.
После заполнения цифровой матрицы соответствующими звуками, получаем арабский цифровой алфавит, в котором мы видим буквы в стилизованном виде почерка насх. Здесь те конфигурации, которые пишутся отдельно, без соединения вправо или влево. Не мудрено, что теперь далеко не во всех буквах мы узнаём цифры. Даже арабские богословы, которые изучают буквы по несколько лет, не могут сообразить, что в арабском языке звуки речи просто пронумерованы цифрами.
Как бы там ни было, арабское письмо – самая простая в мире система письменности. Она до сих пор хранит в себе принципы построения алфавита. Посмотрите, Алиф ا) 1), Вав و) 6) и Та ط) 9) легко узнаются как цифры в любых арабских почерках, тем более, что они сохраняют свои числовые значения. Хорошо просматриваются все девятки. Разве этого недостаточно, чтобы задать вопрос: «А не происходят ли и другие буквы из цифр?» Однако, когда сознание спит, мозг правильные вопросы почти не задаёт.
Таблица 11. Арабский алфавит
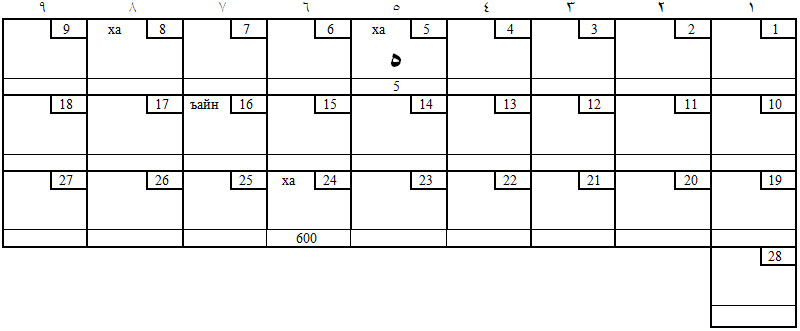
В этом алфавите Вы далеко не во всех буквах увидите цифры:
- во-первых, потому, что он выполнен почерком насх, самым ходовым почерком, а не почерком рукъа, в большей степени отражающим связи букв с цифрами;
- во-вторых, некоторые элементы цифр видоизменились из-за необходимости связывать их между собой;
- в третьих, чтобы видеть цифровую периодичность, надо сгруппировать буквы по периодам (порядкам), чего никто не делает по причине скудоумия.
1.6. Гласные
Арабские буквы обозначают только согласные звуки, гласные обычно не обозначаются, а при необходимости сверху и внизу строки пишут специальные значки, называемые огласовками. Все огласовки ставятся только в словарях и специальных учебных текстах. Отсутствие значков для гласных в обычном тексте отнюдь не мешает чтению. Напротив, огласованные тексты читать труднее, поскольку глаз должен прыгать то вниз, то вверх. Отсутствие огласовок компенсируется знанием грамматики.
Арабских гласных всего три: А, У, И + их долгие аналоги. Долгие гласные обозначаются в строке буквами Алиф ( ا или ى ), Вав ( و), Йа ( ي).
По месту образования в полости рта гласные находятся по краям описанных выше иерархических линий перемещения фокусов артикуляции согласных, т.е. в вершине угла и на концах линий, составляющих этот угол. У – губная, И – среднеязычная и А – гортанизированная.
Едва ли не главной особенностью арабского языка является функциональное размежевание между гласными и согласными. Согласные, главным образом, связаны с передачей лексической идеи, гласные являются показателем грамматики слова, иными словами, отражают связь этой идеи к различным сторонам её включения в контекст, ситуацию, в смысловое поле. Поскольку ситуация и контекст известны читающему, то грамматика слова в арабском тексте не обязательно должна отражаться со всей полнотой. Это и создаёт возможность не ставить огласовки. Они легко восстанавливаются читающим. Критерием правильности чтения является смысл. Если при прочтении того или иного фрагмента текста складывается смысл, значит читающий восстановил упущенные огласовки правильно. Отдельное взятое слово, вне контекста, можно прочитать несколькими способами. Число таких способов иногда достигает десяти и более. Тем не менее, это не создаёт препятствий при чтении, если читающий руководствуется здравым смыслом.
В производных языках гласных больше. Это результат компенсации павших гортанных. Падение гортанных звуков не только сузило звуковую базу языка, но и разрушило грамматику слова. Чтение слова без огласовок стало затруднительным и даже невозможным. Появилась необходимость введения гласных в строку как самостоятельных и равноправных участников структуры слова.
Примечательно, что буквы, обозначающие в арабском языке гортанные, в других алфавитах используются для обозначения гласных. Гортанные в арабском языке занимают следующие позиции: 1, 5, 8, 9, 70, 90, 800, 900, 1000.
Таблица 12. Арабский и русский алфавиты
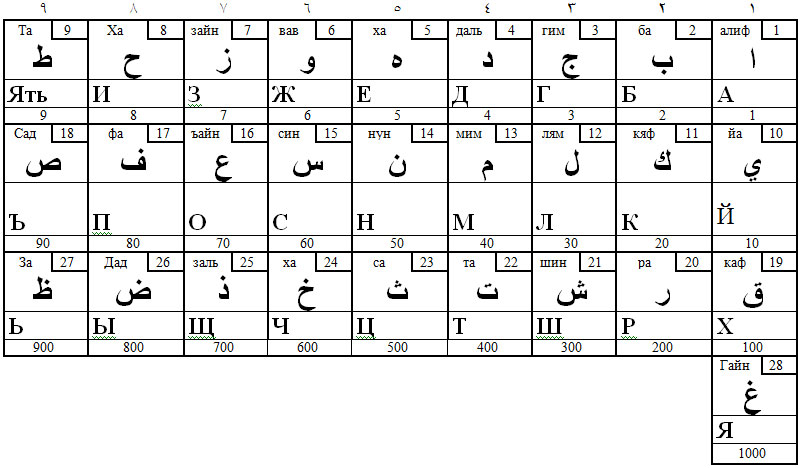
Гортанная номер 1 (хамза ء) в арабской письменности обозначается только в специально оговоренных грамматикой условиях. Обычно она пишется соместно с Алифом (единичкой): ا или с другими "слабыми" буквами (Вав или Йа): و ي.
Правила её употребления достаточно сложны, поэтому её знак ( ء), являющийся редуцированным знаком Ъайна ( ع), практически нигде в новообразовавшихся языках не используется, кроме, пожалуй, еврейской йоты, которая занимает позицию на клеточку ниже (10). В других алфавитах для обозначения этой гласной ( й ) используется арабский алиф с точкой (i).
Гортанная Ха5 в арабском обозначается пятёркой (кружком): ه. В конце слова она пишется с точками, если является показателем женского рода имён: ة , и произносится а(х). Придыхание иностранцами не слышится, потому создаётся впечатление, что это гласный А. Именно этой гортанной обозначается звук А в производных алфавитах. Все варианты этой буквы, включая и рукописные, являются ни чем иным как вариантами арабской буквы X. Сравни: ه. Другие варианты этой арабской буквы дали в производных языках буквы о, е.
На позиции 5 в новых языках стоит гласная Е, её конфигурация взята с позиции 70, где находится арабский Ъайн ( ع ), а на месте Ъайна мы видим букву О. Видно, что произошёл обмен букв между позициями 5 и 70 (О и Е поменялись местами).
На позиции 8 в арабском находится буква Ха8: ح. На числовое значение буквы указывает её начертание, особенно в почерке рукъа. Нижний хвост этой буквы пишется только в конце слова. Если буква соединяется и справа, и слева, она превращается в конфигурацию, точную копию которой мы видим в греческой η (числовое значение – 8 ), если смотреть на неё справа. Латинское h, следующая восьмой по счёту, и наше И8 – есть просто графические варианты той же конфигурации. Что интересно, связь этих букв с цифрой восемь прослеживается только через арабский алфавит. Вне арабского алфавита связь эта становится мистической. Это обстоятельство является ещё одним доказательством первичности арабского письма.
Буква У взята от арабского Ъайна, поставленного на попа: ف . Буква Ю – лигатура, соединение I– десятеричного (Алифа) с О. Буква Э от Е. Таким образом, все без исключения гласные – от арабских гортанных.
Буквы, стоящие на позициях 9, 90, 900 и 800 (двуфокусные) не собственно гортанные, а гортанизированные. Все они изображаются девятками, которые хорошо просматриваются во всех арабских почерках. Падение гортанного фокуса артикуляции привело к почти что полному забвению этих букв. Сохраняется только девятая буква Тэта ( в греческом θ ), которая в еврейском, например, является пустой, поскольку в иврите нет двух разных Т. Сохраняется она в иврите скорее для сохранения числового ряда. К сожалению, несмотря на то что эта буква сохраняет своё числовое значение, никто не видит в ней девятку. Не видят девятку и в более доступном греческом алфавите: θ.
Единственный алфавит мира, сохраняющий все девятки – русский. В древнерусском языке знаками Ять, Ъ, Ь обозначали редуцированные (слабые гласные). Эти знаки вместе с буквой Ы (800) составляют полный ряд Еров.
1.7. Два алфавита
В настоящее время в арабском языке существует два алфавита. Оба состоят из одних и тех же 28 букв, но различаются порядком их следования. В первом алфавите под названием абгадиййа – и он исходный – буквы располагаются в порядке возрастания их числовых значений. Во втором, который называется хуру:ф ат-тахгиййат (буквы тахгият), буквы сгруппированы по общности написания. Он так же, как и первый, начинается с Алифа, но после второй буквы Б ( ب числовое значение – 2) следует не буква Г ( ج числовое значение – 3), а буквы Т и С (ت ث – числовые значения соответственно 400 и 500), поскольку эти последние буквы имеют начертания такие же, как и буква Б. Подряд идут буквы Гим, Ха8, Ха600 ( ج ح خ), так как они различаются только наличием и местом расположения точки.
Понятно, что второй алфавит – производный, является модификацией первого алфавита. Причём, если первый алфавит, пусть и в деформированном виде, отражается и в других языках (арамейском, еврейском, греческом, латинском, русском), то второй существует только в арабском. Правда, он имеет одну общую черту с русским. Вместе с ним он составляет единственную пару алфавитов, которые начинаются с буквы А и кончаются буквой Я.
Название первого прозрачно. Оно происходит от перечисления первых четырёх букв алфавита. Название второго несколько загадочно. Мотивирующий корень имеет два значения: 1 – "перечислять недостатки кого-либо", "критиковать"; 2 – "перечислять буквы", "произносить слово по буквам". На мой взгляд, первое значение этого корня поясняет суть. Ведь перед нами алфавит изменённый, скажем, даже искажёенный по отношению к первичному.
Представляет интерес детальное ознакомление с системой искажений. Если те буквы, которые группируются в одну группу, выписать в столбик, то окажется, что под первые четыре (титульные) буквы подписываются другие, имеющие с титульными общее начертание. В русском начертании это выглядит так.
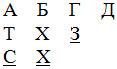
Читая по порядку столбики, получаем последовательность из первых девяти букв А, Б, Т, С, Г, X, X, Д, 3. По-арабски: ذ د خ ح ج ث ت ب ا
Далее идёт 6 столбиков по две буквы: (Ра, 3айн – رز ); (Син, Шин – س ش );
(Сад, Дад – ص ض ); (Та, За – ط ظ ); (Ъайн, Гайн – ع غ ); (Фа, Каф – فق ).
После пар идёт ряд титульных букв без "нагрузки": Кяф, Лам, Мим, Нун. ( ك ل م ن ). Причём этот ряд КЛМН ни в одном из известных алфавитов не имеет искажения. Запомним это свойство.
Далее идёт буква Ха ( ه ), которая по начертанию одинакова с нашей буквой О, что ещё раз вызывает удивление из-за совпадения в последовательности. Замыкают алфавит так называемые "слабые" Вав и Йа (Я) – و ي .
Пронумеруем столбики так, чтобы носителями номеров были только титульные буквы. В этом случае обнаруживается удивительная вещь.
Таблица 13.
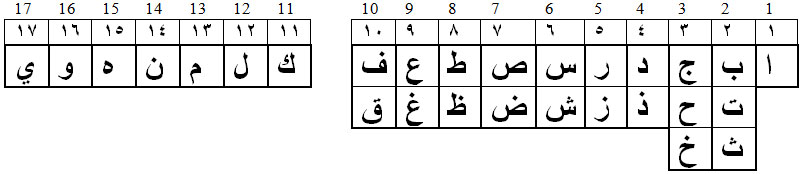
Буквы первой четвёрки (А, Б, Г, Д – د ج ب ا) стоят на своих местах (1, 2, 3, 4). То же по отношению и к четвёрке КЛМН – ن م ل ك. Она занимает соответственно позиции 11, 12, 13, 14. Точно такие же, какие она занимала в счётном алфавите! Вряд ли это случайность. Ведь при обычной раскладке эти буквы занимают позиции 22, 23, 24, 25.
Таблица 14.

Во втором алфавите титульных букв будет всего 17. Причём, они выстраиваются в два периода. Один период – сжатый, второй – обычный. Пожалуй, заслуживает внимание ещё то, что данный буквенный ряд закольцован. Он кончается буквой Я ( ي), которая может быть помещена в один столбец с буквой Алиф максура ( ى ), которая является русским Алифом (гусем), что явным образом, напомню, отражается в названии (маКСУР – РУСК).
Рисунок 3. Превращения Великого Гоготуна в Алиф
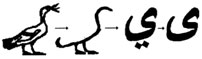
Что же произошло с алфавитной матрицей? А произошло её сжатие. Вместо трёх полос матрица сжалась до двух неполных. Но что характерно, начальная четвёрка согласных АБГД, как оказывается после снятия "камфуляжа", остаётся на своих позициях. То же и по отношению к четвёрке согласных КЛМН. Она осталась во втором периоде и на своём месте.
2. Лексико-грамматическое развёртывание языка. 6 уровень
Словообразование и синтаксис описываются в нормативной грамматике, которую я подменять не собираюсь. Но общие принципы словообразования на начальных этапах развёртывания её, в особенности не описанные в грамматиках, упомянуть следует.
2.1. Корень и словообразование
Арабский корень имеет жёсткую структуру и обязательно включает три согласных, которыми выражается некая идея, предположим, открытия (корень حتف – ФТХ). Имеется также система четырёхсогласных корней, однако она менее распространена по причине её слабой мощности в смысле словообразования и ограниченных семантических возможностей. Её мы здесь касаться не будем.
Огласовки корневых согласных, часто совместно с дополнительными, некорневыми согласными, выражают грамматику слова, т.е. отношение данной идеи к описываемой словом ситуации, её участникам и её параметрам, таких как время, модальность, залог и т.п. При этом гласные, если нет особой необходимости, на письме не обозначаются. Так, ФаТаХа ( حتف ) означает "он открыл", ФуТиХа ( حتف ) – он был открыт", ФаТХ – "открытие" и т.д. Все эти формы слова пишутся одинаково: ( حتف ). Контекст позволяет легко отличить одну форму от другой.
Глаголы, основа которых состоит только из корня, называют непроизводными, или глаголами первой породы. От первой породы образуются глаголы производных пород. Всего пород – 15. Но обычно в нормативные курсы включаются только десять наиболее распространённых пород.
Производные породы образуются путём внедрения в состав слова аффиксов (некорневых морфем) либо удвоением средней корневой (вторая порода), либо удлинением первой огласовки (третья порода). Пример образования второй породы от первой: حتف фатаха "он раскрыл": حتف фаттаха "он пораскрывал". Пример образования третьей породы от этого же корня: حتف – фа:таха "он раскрыл себя кому-то, он признался".
От глагола первой породы можно образовать имя действия (масдар), имя деятеля (причастие действительное), имя поддейственного (причастие страдательное), имя орудия, имя времени и места, имя способа совершения действия, имя остатка, имя болезни и некоторые другие имена.
От глаголов производных пород образуется имя действия (масдар), оба причастия и иногда имя места (совпадающее по форме с причастием страдательным). Большинство арабских слов относятся к одной из перечисленных здесь категорий. Каждая из них имеет особую формулу образования. Например, حتف мифта:х, "ключ" – является именем орудия первой породы корня ФТХ "открывать", حتف фа:тих "открывающий" – причастием действительным этой же породы. Соответствующая формула определяется по конфигурации огласовок и по включённым в слово некорневым согласным. Основу всего словообразования составляет система пород.
Типы корней и корнеобразование.
Арабские корни подразделяются на сильные и слабые. Слабые корни содержат в своём составе слабые согласные (полугласные). Это Й – ي и В – و (напомню, произносится как английское W). К их числу можно отнести и Хамзу – ء, поскольку этот звук так же, как и слабые, вносит в формулы определённые изменения.
В зависимости от места слабой в корне, корни подразделяются на:
- подобноправильные, если слабая занимает первую позицию, например, لسص ВСЛ васала "прибывать";
- пустые, если слабая занимает вторую позицию, например, корень نک КВН "бытие";
- недостаточные, если слабая занимает третью позицию в корне, например يش МШЙ "идти".
Наличие слабой в корне сильно модифицирует формулы словообразования, о которых шла речь выше, но по довольно жёстким правилам. Слабые согласные, в зависимости от модели слова, могут редуцироваться до гласных, долгих или даже кратких, и, следовательно, как и любые краткие гласные, могут не обозначаться на письме. Слабые могут переходить друг в друга или в Хамзу, тоже, впрочем, по определённым правилам. Так, глагол от نک каун "бытие" в прошедшем времени пишется и произносится ناک ка:на "он был", где корневой Вав подменяется Алифом; повелительное наклонение для второго лица мужского рода пишется только в две буквы: نء кун "будь"; в причастии действительном слабая Вав подменяется Хамзой: ناک ка:'ин. Как видим, в разных формах слова слабая то появляется, то исчезает, то вновь появляется, но уже под масками других букв.
Около полуторы тысяч арабских корней, что составляет примерно четверть всех имеющихся, – слабые. Именно от них образуются наиболее употребительные слова, так что, по меньшей мере, каждое третье слово в тексте образовано от слабого корня и поэтому маскирует место и качество слабой корневой. Это обстоятельство значительно затрудняет чтение арабского текста, и даже нахождение слова в словаре. Большинство арабских словарей составлено по корневому принципу. Все слова от одного корня помещаются в одной статье, иначе, слова группируются в алфавитном порядке корневых согласных. Тот, кто читает текст на арабском языке, постоянно ведёт анализ слов с точки зрения состава его корневых согласных. Критерием правильности такого анализа является складывающийся смысл читаемого. Если смысл не сложился, значит где-то ошибка, либо в определении огласовки, либо в определении корня.
Всё, что было здесь сказано о корнях и о словообразовании, можно найти в любой грамматике арабского языка. Но вот как образуются сами корни – этот вопрос до сих пор оставался не выясненным, хотя попыток в этом направлении было предпринято немало. Ещё в раннее средневековье арабские грамматисты пытались представить значение корня, как сумму значений корневых согласных, предполагая, что каждая согласная имеет своё собственное значение. Далее нескольких правдоподобных примеров дело не пошло. К счастью, арабы быстро сообразили, что идут по тупиковому пути, и не стали строить на этом болоте эзотерическую теорию, хотя поводы для этого в арабском языке можно найти гораздо более основательные, чем в еврейском, где выстроено бестолковое учение под названием каббала. В русском и украинском подобные теории сейчас, после развала СССР, стали расти, как грибы.
Ошибка арабов состояла в том, что они видели лишь механическую сумму сложения, не замечая, что кроме сложения, в корне происходят процессы свёртывания. Чтобы пояснить, о чём идёт речь, возьмём, к примеру корень КВМ, от которого в арабском قک ку:ма "куча". Образуем от него путём удвоения среднего корневого глагол второй породы: مک каввам "нагромождать, сваливать в кучи", "накапливать". Теперь вставим в корень согласный Р, имеющий то же значение, что и вторая порода. Получается корень مکو РКМ "сваливать в кучи", "накапливать". Поскольку в корне только три места, слабый согласный Вав свернулся. Кажется, что его нет. На самом деле за РКМ стоит Р + КВМ. И едва мы отделим Р, снова в корне появляется слабый. Арабы этого не учитывали, и потому при попытке отделить некоторые буквы, в остатке у них оставался двухсогласный корень КМ. Такой механический подход и не позволил им вскрыть механизм корнеобразования.
Не заметили арабы и того, что список аффиксальных согласных, а его выявить не трудно, если знаешь принцип, в целом семантически копирует систему пород, что значительно облегчает их выявление. Взятый нами согласный Р по значению точно соответствует второй (интенсивной или каузативной породе). Так и другие аффиксальные согласные, внедряющиеся в корень. Их около десяти. Р ( و ) соответствует второй породе, Д ( ل ) – третьей или шестой, X( ح ) – десятой и т.д.
Но что интересно. Если в начале процесса наращивания аффиксальных согласных мы имели корень, состоящий, предположим, из одних только слабых, то все корневые постепенно, один за другим, могут быть вытеснены аффиксами, в результате мы получим корни, целиком состоящие из аффиксов, но значения полученных корней вытекают не столько из значений аффиксов, сколько из значения первичного корня. И это несмотря на то, что ни одного корневого в явном виде в корне уже нет.
Такой пример. Идея округлости, вращения, поворота выражена в корне ءالو вара:' "назад". Причём, по всей видимости, Р здесь просто усилитель, а корень тот же, что в русском вить. Корень принимает аффикс Д и превращается в لود ДВР, от которого глагол первой породы راد да:ра "вращаться", "поворачивать". От него образуется десятая порода: راسا 'истада:ра "становиться круглым". Функцию внешнего аффикса ист – выполняет внутренний X ( ح ), Механически заменяем аффиксом Xаффикс десятой породы 'ист, получаем корень رصد ХДР "становиться круглым". Итак, постепенным внедрением в корень один за другим аффиксов Р, Д, X получен корень ХДР, состоящий из одних только аффиксов, однако главный стержень в значении данного корня, идея округлости, остался, хотя ни одного корневого здесь нет. Корень вить как бы исчез или свернулся, но только формально. В звуковом отношении, семантически он продолжает присутствовать в полном объёме, и именно он определяет, главным образом, семантику слова. Аффиксы вносят в корень лишь дополнительные оттенки, которые, кстати, по причине своей малозначимости, могут легко десемантизироваться, выветриться в реальном употреблении слов. Так, в приведённом примере значение интенсивности в аффиксе Р стёрлось. Уже в глаголе راد да:ра этой семантики нет. Ведь глагол обозначает не только интенсивные вращения, но любые, и даже вялые.
При всём этом необходимо учитывать, что обогащение корней семантикой (значениями) происходит не только и не столько в результате их аффиксальной обработки, сколько в реальном употреблении в речи. Предположим, мы обозначили неким словом некую вещь, исходя из того, что значение слова отражает какой-то броский признак вещи. Ну, например, птицу, известную своей клептоманией, назвали "воровкой", что по-арабски называется ةؤوس сарука, т.е. сорока. Но так не бывает, чтобы у вещи был один всего лишь признак. Дело в том, что слово "сорока" потенциально уже обозначает не только клептоманию, но саму вещь как таковую вместе со всеми её признаками. Говорят: "Трещит как сорока". За сорокой теперь уже не воровство, а совсем другое качество. Как в телекамере луч снимает потенциал с освещённой так или иначе ячейки фотоэлемента, так и слово снимает признаки с реальных (или вымышленных) вещей.
В слове надо различать этимологическое значение и коммуникативное. Этимологическое значение – это то, которое явилось причиной приложения данного слова к данной вещи. Оно у слова одно. Коммуникативные значения – это те значения, которые указываются в толковых и двуязычных словарях. Их обычно много. Почти все они – результат либо переосмысления исходного этимологического; либо это значения, снятые с реальности. Малина, вероятно, названа по мягкости, от арабского نيط мулаййан "размягчённый" или мали:н "мягкий", поскольку эта ягода легко уминается. Но малиновый уже означает не "мягкий", а "цвета малины" или "приготовленный из малины".
Здесь важно понять, что каждый раз, когда в дело вступают аффиксы, они обрабатывают корень и вступают во взаимодействие не обязательно с тем значением, которое идёт именно от корня, но и с приобретёнными значениями, и, главным образом, с ними. У нас собака названа по функции, по её использованию в собачьих бегах (от قاب сиба:к "гонки"), но собачиться – это совсем не участие в бегах, а нечто другое.
Кроме аффиксального способа корнеобразования имеется другой, называемый в специальной литературе аллотезой. Имеется в виду изменение звучания слова, в частном случае изменение звучания какой-нибудь согласной корня. На русском материале: кристалл, хрусталь. Это явление можно найти в любом языке, но в арабском оно представлено в более массовом виде и касается только согласных корня. Как правило, отклонение звучания, если это действительно аллотеза, происходит в пределах гоморганности звука. Т.е. произношение меняется, но произносится слово тем же органом речи, например, губами. Если аллотеза сопровождается изменением значения, то этот процесс имеет непосредственное отношение к корнеобразованию. Загадочным это явление не представляется, и дело здесь лишь за тем, чтобы в этимологическом исследовании оно было учтено.
Если из общего количества корней арабского языка мы постепенно будем изымать корни производные (по мере их выявления), то в постоянно сужающемся круге корней мало помалу начинает проявляться тот исходный принцип генерирования корней, который нас должен привести к началу.
Но сколько бы мы ни извлекали аффиксов из состава корня, в остатке никогда не получается менее трёх согласных. Этот эффект объясняется двумя факторами. Первый – восстанавливаются свёрнутые слабые. Второй состоит в том, что в арабском языке любой звуковой материал, даже состоящий всего лишь, на наш взгляд, из одной гласной, автоматически становится состоящим как бы из трёх согласных, если только он мыслится в качестве знаменательного слова.
Поясню на примере. Предположим, звучит гласная А, передающая некую идею. В этом случае переход от "незвука" к звуку, т.е. само начало произношения, воспринимается как согласный хамза. А схождение звука на нет становится придыханием, т.е. звуком Х5 (٥). Что же касается самого гласного звука, то он воспринимается как долгий, независимо от реальной долготы звучания, поскольку в закрытом слоге любая долгота произносится кратко. В свою очередь, за любым долгим мыслится слабый (Вав или Йа). Итак, заимствовав, допустим, из какого-то языка слово а, арабский язык автоматически превращает его в трёхсогласный комплекс, не меняя его звучания. Причём, и записывается это слово в три знака: هاء (в транскрипции: 'а:х).
Далее выясняется, что базовые корни группируются вокруг согласных, которые назовём опорными. Это, как правило, согласные передние. При произнесении этих согласных так, чтобы рот раскрывался, они образуют корни, означающие раскрытие, расширение, распространение и т.п. Если же эти же согласные произносить наоборот, то есть с закрытием рта, то образующиеся при этом корни означают нечто противоположное: "закрытие, сужение". В арабском языке найдено около 50 пар корней, прекрасно иллюстрирующих это положение. Вот на русском материале: от – до (с закономерным сопутствующим оглушением на конце от), зев(ать) – вяз(ать). На арабском: مض дамм "стягивать", دض мадд "растягивать". Затем эти корни обрабатываются различными аффиксами, а также происходят их изменения по принципу аллотезы. Значения корней постепенно уходят от первоначальных (например: расширяться > распространяться > расходиться > путешествовать; другая линия развития от этого же корня: расширяться > разжижаться > жижа > грязь > плохо, считать плохим > ругаться). Эта схема воплощена в конкретном звучании СА. В конце первой линии развития стоит русское "сваха" из выражения "переезжая сваха", где на самом деле не сваха, а арабское слово ةداس – савваха "путешественник"; в конце второй линии – русское "сетовать", производное от арабского ءاطسا иста:' "сетовать" (восьмая порода от ءس са:' "быть плохим", откуда ىءس су', "плохость" и откуда в русском "суеверие", "суета"). Но разве скажешь, что все эти русские слова – родственники, если видишь лишь вершины корневых связей? Разве скажешь, что в "сетовать" звук т не является корневым? Тем не менее, все эти шаги эволюции семантики и звучания достаточно точно прослеживаются на арабском материале вплоть до самого начала. А в начале процесса корнеобразования, как было сказано, лежит звукоизображение. СА – "расширение", АС – "сужение", ср. русское "ось" (довольно близкий родственник "сетовать"). Речевым аппаратом в начале корнеобразования изображается то, что обозначают соответствующие органы речи. А изображаются пульсации, переходы от точки к окружности и наоборот, изображается символ развёртывания точки в окружность. Ведь рассмотренный в начале угол есть лишь момент развёртывания точки в шар. Именно по этой схеме разворачивается корневая система арабского языка.
При реконструкции корневой сети выясняется также, что все корни родственны. Понятие корня, как некоего застывшего звукового комплекса, как это принято в языкознании, не имеет смысла. Корневая система языка больше напоминает корневую систему дерева, где корни не точки (глазки), а связи, жилы, имеющие ответвления. И все эти ответвления, в конечном итоге, сходятся в одной точке, в точке начала, в точке нуля. Кстати, в Вавилоне нуль изображался окружностью с точкой в его центре.
Как далеко заходят родственные связи слов в русском языке, языке явно производном в своей основе от арабского? Через посредство арабского языка в родственные отношения были поставлены более тысячи русских непроизводных слов, то есть таких, которые не имеют явного родства со словами других корневых гнёзд, так что корневое родство – тотальное свойство и русского языка.
Таковы некоторые особенности структуры арабского языка, Ассемблера общечеловеческого языка. Чтобы не быть голословным, рассмотрим фрагмент Ассемблера, получение кода операции вращением или прибавлением единицы, что одно и тоже.Обратите внимание: компьютер работает с единичками и ноликами, а человек из-за ограниченности в ресурсах4 – с мнемоническим кодом. Решение одних и тех же проблем, задач приводит к использованию подобных приёмов и методов в силу единства Вселенной и законов Бытия.
Таблица 15.
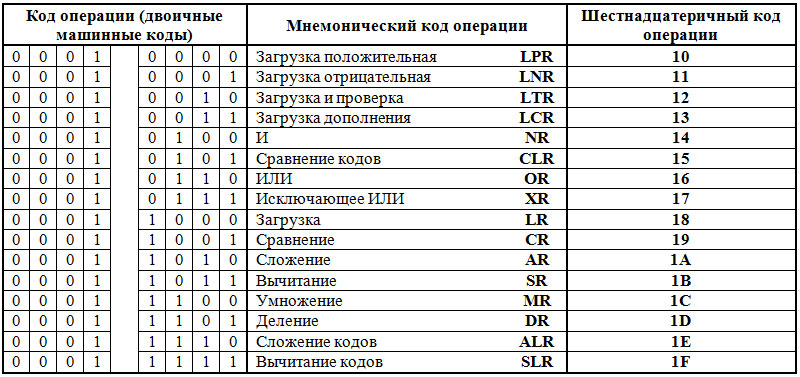
Анализ процесса программирования на Ассемблере дает ещё массу аналогий со схемой развития этнических языков.
2.2. Язык и инстинкт
Теперь об инстинктах. Инстинкты, разумеется, никакого отношения к языку не имеют. Это логика учёного люда. Однако соглашаться с учёными погодим. И прежде чем приводить какие-либо доводы, опишем как устроен язык в целом. Язык можно представить в виде некоего шара, ядро которого составляет корневая система. Отвлечёмся сейчас от того, что она имеет два начала (арабское и русское) и от того, что арабский корень не имеет признаков частей речи. Он носитель общей идеи в отвлечении от глаголов и имён. Итак, есть ядро. Ядро корней скрыто толстым слоем словообразовательной системы, который покрыт синтаксисом, позволяющим строить осмысленные предложения. Всё это сверху покрывается механизмом текстообразования. Это у человека.
У животных все верхние слои сняты – речь отсутствует. Остаётся один внутренний клубок корней со слабыми остатками словообразования.
Так вот, занимаясь исследованием корневой системы арабского языка, обнаружили, что корни имеют между собой семантические связи, так что если собрать все родственные корни, то можно увидеть, как постепенная деривация их семантики рисует тот или иной инстинкт, притом часто в его динамике. По сути эта цепочка, иногда весьма разветвлённая, является не чем иным, как последовательностью языковых команд для исполнения определённой программы, содержащей сценарий поведения. Что позволяет утверждать: корневая система арабского языка – развитие и отображение инстинктов животных – доступна животным, существует в их мозгу. Но отличается, как одно поколение компьютеров от другого.
Можно говорить об особом синтаксисе корней. Чтобы не быть голословным, приведу примеры:
ودب – БДВ – "казаться, виднеться";
دب – БЪД – "быть далёким", "удаляться";
ددب – БДД – "убегать";
أدب – БД' – "начинать";
ردب – БДР – "делать первым", проявлять инициативу";
دب – БДЪ – "делать то, чего ещё никогда не было", "творить".
دب – ЪБД – "быть рабом";
دبأ – 'БД – "дикое животное";
دبو – ВБД – "быть бедным", несчастным", "обидеть".
Это лишь некоторые корни и некоторые их значения, позволяющие получить представление об инстинкте ориентирования в сложной ситуации появления вдали некоего объекта, сулящего возможную беду, как-то: дикое животное, рабство. Надо принять решение: либо первым напасть (БДР), либо убежать (БДД), либо, как говорится, найти нестандартное решение (БДЪ).
Ещё деталь, если корень БД с разными наполнителями читать в обратную сторону, получим ряд понятий противоположного свойства: "близость", "доброта", "домашнее животное" и т.д. В русском: БЕДА – ДОБРО. К этому же семейству корней относится русское: будить и бодрствовать.
Другие цепочки корней (в сокращённом варианте):
بقن – НКБ – "пробивать дырку";
رقن – НКР – "стучать", "бить клювом";
دقن – НКД – "клевать", "критиковать".
خقن – НКХ – "разбить голову", "вытащить мозг из кости";
خقن – НКХ – "вытащить мозг из кости", "обглодать", "очистить ствол от листьев".
قن – ЪНК – "узкий проход", "горлышко", "горло", "шея";
يقن – НКЙ – "очистить".
Как мы видим, налицо – постепенный переход от "стучать", "пробивать дырку" до "доставать костный мозг", "очищать" через "узкий проход", "шея". Это запись технологической цепочки добывания пищи падальщиками. Думаю, что читатель не станет возражать, если я скажу, что смыслы, рисуемые данной совокупностью корней, доступны и животным, и что животные действуют именно по этой схеме, пусть и с некоторыми сокращениями.
Похоже, что и кровососущие привязаны к той же цепочке. В английском от этой цепочки есть слабые пролазы: nock "стучать" и neck "шея". Но разве кому придёт в голову сказать, что эта английская парочка – ближайшие родственники?
Смотрите, какое "изящное" отвлетвление от шеи: قنض ъанака "обнимать", قنض ханака "душить", قنش шанака "вешать". Есть ещё один отросток, сексуальный: نك на:к "иметь женщину", حكن наках– то же. Обратите внимание, как крепко сексуальный инстинкт привязан к пищевому.
Паук (паучиха), по-арабски طوبىن ункубу:т, во время брачевания, что по-английски называется фак (ср. паук, от арабского حبق факаъа "прокалывать") душит в своих смертельных объятиях возлюбленного, как будто знает арабский язык! И английский! Что же её заставляет поступать столь жестоко? А поиски смысла. Ведь корень قنى КНГ означает "тайный смысл". От этого корня у нас "книга". Смысл сильнее и важнее смерти. А смысл простой: обеспечить выживание потомству.
2.3. Физиологическая функция алфавита
Отметим, что четвёрка согласных КЛМН выполняет особую функцию в физиологическом механизме воспроизводства человека. В частности, буквы М, Н занимают 13 и 14 позиции, что соответствует 13 и 14 дню менструального цикла. Это наиболее благоприятные дни для зачатия, поскольку корень МН образует слово мана: "сперма". Чтобы зачатие произошло, сперма должна попасть на свои клеточки. Вот почему порядок и место букв КЛМН не меняется.
В цифровой алфавитной матрице воплощены идеи не только игральных карт, шахмат, земной, бренной жизни, но также совмещены два календаря: солнечный и лунный. Девять месяцев беременности (девять цифр) проецируются на развёртку лунного месяца, состоящего из 28 дней. Этот же цикл определяет и срок беременности (280 дней). Именно эта матрица, имеющаяся в мозгу каждой женщины, а не физическая луна, является пусковым механизмом менструального цикла, иначе у всех женщин менструальные циклы были бы синхронизированы. Об этом говорит и название первой буквы по-русски – Аз, что соответствует арабскому زو– вазз "гусь", который по всем поверьям, снёс золотое яичко, из которого развернулась Вселенная. Эта буква и запускает механизм овуляции: появление в женском организме яйцеклетки. Эта же буква своим номером (числовое значение – один5) вызывает красный цвет, что является командой для прилива в матку крови с целью вымывания из неё старой неоплодотворенной яйцеклетки.
3. Развёртывание этнических языков. Этногенез. 7 уровень
Схема развёртывания языкового разнообразия весьма напоминает таблицу химических элементов по Бору (10, т. 19, с. 415). Таблица Бора отличается от таблицы Менделеева тем, что отдельные внешние строчки помещены вовнутрь таблицы, так что общий вид таблицы Бора напоминает веер, в вершине которого две точки: Гелий и Водород. Гелий держит линию инертных газов, а водород как бы распадается веером на остальные элементы, заполняющие таблицу. Первый период таблицы точно соответствует солнечной плазме, состоящей, как известно, главным образом, из водорода и гелия. Совокупность двух языков, арабского и русского, я бы назвал языковой плазмой, где гелию соответствует арабский язык, мало меняющийся и консервативный, чуждающийся заимствований, а водороду – русский, подвижный, с размытой грамматикой, легко взаимодействующий с другими языками.
")
Уже в структуре арабского языка заложен механизм глоттогенеза (образования языков) и, соответственно, этногенеза. Почти треть арабских согласных произносится слабоуправляемыми задними органами речи, что объективно создаёт предпосылки к их падению (по закону экономии усилий) и замещению передними звуками, объективно более простыми в произношении, поскольку они произносятся подвижными и тонко управляемыми органами речи (языком, губами).
Любая группа людей, выходя из орбиты влияния арабских традиций и установлений институтов арабского общества, упрощает произношение звуков, что приводит к структурным деформациям. Эти деформации затрагивают структуру корня и, следовательно, всю грамматику слова. После падения гортанных корень перестает быть трёхсогласным, гласные застывают и сливаются с корнем, теряя свою грамматическую функцию. Теряя грамматическую жёсткость, язык становится более терпим в отношении заимствований, что ещё более разъедает первоначальную структуру языка. Падение гортанных компенсируется, к примеру, развитием звуков передней артикуляции. Слова всё более удаляются от своего первоначального звучания.
Похоже, что первым языком, утратившим гортанные, был русский. Подвергнувшись изменениям, он показал другим языкам путь к изменениям. Так по этой схеме постепенно образуются всё новые языки, а с ними и новые этносы – народы. Сам собой напрашивается вывод: перед нами – единая система, завязанная на цифры, языки, этносы, культы. Следовательно, для того, чтобы понять ход эволюции человечества, следует разобраться с языком и письменностью.
4. Слово и число
Великий, могучий русский язык. С этим утверждением мы знакомимся ещё в школе, но, к сожалению, не всегда можем понять и объяснить в чём же величие и могущество нашего русского языка. Хорошую подсказку в познании тайны русского языка даёт нам древняя наука нумерология и простая арифметика.
В чём же они объединяют и дополняют друг друга? Для дальнейших рассуждений и подсчётов воспользуемся следующим алгоритмом:

Каждой букве алфавита соответствует своя цифра. Возьмём любое слово, сложим все цифры, соответствующие буквам в этом слове и получаем число. Слов, которые имеют одно и то же число достаточно много. И вот здесь начинается самое загадочное, таинственное и интересное.
СЛОВО (14737) = 22
Слова, также имеющие число 22 – ДИАЛЕКТ (22), ДИАЛОГ (22), ДИСКУССИЯ (22), ЛИНГВИСТ (22), ЛОЖЬ (22), ЛОМАТЬ (22), ЛЬСТЕЦ (22), и т.д.
Слово МАМА (5151) имеет число 12. Это же число 12 имеют следующие слова:
СВЕТ (12), ВСТАТЬ (12), ДЫМ (12), МУКА (12), ЕДА (12), ИМЯ (12), ЕСТЬ (12), МЫТЬ (12), НАЙТИ (12), НАМ (12), НИТЬ (12), УСТАТЬ (12), РАЙ (12), ТАЙНА (12), ИСТИНА (12). Все эти слова не только имеют одно число 12, но подходят друг другу по смыслу. Мама встаёт рано, чтобы приготовить еду, будит детей, кормит, убирает. Мама связана с ребёнком астральной пуповиной пожизненно (т.е. нить) и всегда чувствует, когда с ребенком нелады.
Слово ПАПА (8181) имеет число 18. Это же число 18 имеют следующие слова: КАРКАС (18), МЕЧ (18), СЕМЯ (18), СЕЯТЬ (18), СУДЬЯ (18). Отец – опора семьи, защита, продолжатель рода, добывает хлеб, хозяин в доме. И здесь полное соответствие числа и смысла.
МАМА (12) + ПАПА (18) = ВДВОЕМ (30), ДОБРО (30), СОЛНЦЕ (30), ИДЕАЛЬНЫЙ (30), СЕМЕЙНЫЙ (30), КЛАДОВАЯ (30),
Если мы рассмотрим полную семью МАМА(12) + ПАПА(18) + СЫН(9) + ДОЧЬ(22) = 61, то получим число 61. Это же число 61 имеют слова: ПРЕВОСХОДНЫЙ (61), ПРОДОЛЖАТЬСЯ (61). Сложив цифры 6+1 получаем число 7.
Число 7 означает СИЛА (1141). Семья – это сила, опора рода.
Что это – случайное совпадение, или какая-то скрытая система?
Продолжим наши рассуждения.
Слова РУССКИЙ (20) ЯЗЫК (20) имеют каждое число 20. Сложив цифры 2+0 получаем 2. Двойка это двойственность, дуальность, дихотомичность, инь-ян, проблема выбора и соответствующий выбору результат. Какой же выбор предоставляет нам русский язык. Язык – это слово, а вот словом можно исцелить, а можно убить. Старые прописные истины. Итак, слова имеющие число 20, выбор за нами:
- ВЕДАТЬ (20), ЯСНО (20), УСВОИТЬ (20), ЧИСЛО (20), УЧЕБА (20), БОГАТЫЙ (20), БОЖИЙ (20), ВЕЛИКИЙ (20), СВЕТЛЫЙ (20), НАЦИЯ (20);
- ЛЖИВЫЙ (20), ИСПЫТАТЬ (20), ЗЛО (20), ЗАВИСТЬ (20), НАСИЛИЕ (20), ИНСУЛЬТ (20), ПСИХИКА (20), ХУДО (20), УХОД (20), ГИБЕЛЬ (20), РИТУАЛ (20).
Здесь мы видим уже не только смысл, но и путь с окончательным результатом сделанного нами выбора.
Если сложить числа 20 (РУССКИЙ) и 20 (ЯЗЫК), то получим число 40. И здесь нам предоставляется выбор пути – беречь свой язык, изучать его, с энтузиазмом творить и крепнуть. Либо растратить это наследие, потерять, и погибнуть. Следующие слова, имеющие число 40:
- ОСНОВАТЕЛЬ (40), ПИСЬМЕННЫЙ (40), ПОСТРОИТЬ (40), КУЛЬТУРНО (40), КРЕПНУТЬ (40), МОЩНОСТЬ (40), ОБЕРЕГАТЬ (40), ВОЛШЕБНЫЙ (40), ОБРАЗЕЦ (40), ТВОРЕНИЕ (40), ФЕНОМЕН (40), ПОЧЕРК (40), ПРИРОДА (40), РОДОВОЙ (40), ЭНТУЗИАЗМ (40);
- ПРОТИВНИК (40), УГНЕТЕНИЕ (40), НЕДОСТАТОК (40), МАЛОДУШНЫЙ (40), НАРУШИТЬСЯ (40), ПАТОЛОГИЯ (40), ПОШАТНУТЬ (40), ПОГРОМ (40), РАЗВАЛИТЬСЯ (40), РАЗДОР (40), УНИЧТОЖИТЬ (40), УРОДОВАТЬ (40), ДЕМОНТАЖ (40), ИЗОЛЯЦИЯ (40), ОТМЕРЕТЬ (40), ПОЗОР (40), ПРОСТИТЬСЯ (40), ХОРОНИТЬ (40), СОЖАЛЕНИЕ (40), ЖИВОТНОЕ (40).
Слово ОБМАН (21) «роднится» с такими словами, как ТАБЛЕТКА (21) (табу – лета), АПТЕКА (21). Поэтому с помощью таблетки никогда здравых лет себе не прибавишь.
А вот слово ЛЕКАРСТВО (36) роднится с такими словами, как ЧЕЛОВЕК (36), ЭНЕРГИЯ (36), ПШЕНИЦА (36), ПЕЧЕНЬ (36), ЖЕЛУДОК (36).
А если современный человек, не понимая истинного смысла слова «таблетка», пытается получить от государства, или от кого-либо БЕС-ПЛАТНОЕ (платит бес) лечение, то взамен он получит следующее:
БЕСПЛАТНО (37) = НЕЧИСТАЯ (30) + СИЛА (7), БЕЗУМЕЦ (37), БОЛЕЗНЬ (37), ГРЕШНИК (37).
В результате – опять ОБМАН (Бес + Сатана).
Гораздо благозвучнее слово БЕЗВОЗМЕЗДНО (74) (без возмездия) дружит со словом БЛАГОТВОРИТЕЛЬНОСТЬ (74) (благо творить), ПРЕДПРИНИМАТЕЛЬ (74).
С давних пор считается, что число 13 несчастливое, опасное, невезучее. Наверняка вы обратили внимание, что слова БОГ, ДУХ имеют число 13. Все цирковые арены имеют диаметр 13 метров, и вряд ли люди, показывающие чудеса владения телом высоко под куполом, выбрали бы себе такое «несчастливое» число. Это опять информация к размышлению: опираться на приметы, рождённые за границей или довериться родному языку.
ИЗБА (13), ЕЛЬ, КАША, САЛО, КЛАД, СМЫСЛ, ФЛАГ.
БОГ(13), ДУХ (13)=ШАГ (13)
МИНА (13), КПСС, РАК, СИФИЛИС, СЕКТА, СЛУГА, СВАЛКА.
Интересно также окружение числа 13. Его соседом с одной стороны стоит число 12 СВЕТ, и с другой стороны, число 14 ЖИТЬ. Получается – СВЕТ(12) – БОГ (13) – ЖИТЬ (14).
Обратная сторона этой триады – ЯМА (12), РАБ (12) – СЕКТА (13), УЖАС (13) – КНУТ (14), ХАОС (14). Это как две стороны одной монеты – с одной стороны СВЕТ – БОГ – ЖИТЬ, а с другой РАБ – УЖАС – КНУТ. И никогда Бог и Раб не будут существовать вместе, Раб всегда будет от Бога с противоположной стороны.
Слово ТЬМА (11) стоит рядом со словом СВЕТ (12). Слово СМЕРТЬ (26) рядом со словом ЖИЗНЬ (27). Как видим, числовое и смысловое соседство.
Впечатляет, не правда ли!
Общественные явления
Если проанализировать негативные общественные явления, такие как пьянство, накромания, проституция, то и здесь русский язык заблаговременно предупреждает людей об этой опасности, о том результате, к которому они придут, если встанут на этот путь.
ВОДКА (19) – ВОЙНА (19), ССОРА (19), ДРАКА (19), СКАМЬЯ (19), ВДОВА (19)
ВИНО (17) – ЛИХО (17), МАГИЯ (17), ЛГУН (17), ВИРУС (17), БАНДИТ (17)
Если сложить ВОДКА (19) + ВИНО (17) = ПЬЯНСТВО (36)
Смысловой ряд слов, имеющих число 36, показывает нам путь и результат пьянства:
ПЬЯНСТВО (36) – ЧЕЛОВЕК (36), АГРЕССИВНЫЙ (36), ЭНЕРГИЯ (36), БЕСЧИНСТВО (36), РАЗНЯТЬ (36), УКОЛОТЬСЯ (36), ПЕЧЕНЬ (36), ОПАСНОСТЬ (36), КОВАРСТВО (36), ДЕСПОТИЯ (36), ЗАПАДНЯ (36), ЗАПУТАТЬСЯ (36), ТОРГОВЫЙ (36), ПРИЛАВОК (36), СООБЩНИК (36), ВОР (36), РАПОРТ (36), СЛЕДСТВИЕ (36), ОРДЕР (36), ЗАСЕДАНИЕ (36), НАЗНАЧИТЬ (36), ПЕРИОД (36), КОНВОИР (36), ОТПРАВИТЬ (36), ПРЕБЫВАТЬ (36), КАЗЕННЫЙ (36), МОНАСТЫРЬ (36), ЛИХОРАДКА (36), ПАПИРОСА (36), ОСОЗНАТЬ (36), НАПРАСНЫЙ (36), ГОРЕЧЬ (36), ПОГИБНУТЬ (36), БУМЕРАНГ (36).
ВОДКА (19) + ВИНО (17) + БЕС (9) = АЛКОГОЛИЗМ (45)
Комментарии излишни!
Слово НАРКОТИК (32) предостерегает нас:
НАРКОТИК (32) – АЗАРТНЫЙ (32), ДУРНОЙ (32), БЕЗУМИЕ (32), СУЩНОСТЬ (32), ТЕРЗАТЬ (32), ЖЕЛАНИЕ (32), БРОСИТЬЯ (32), СОУЧАСТНИК (32), ВДОВОЛЬ (32), ГЛУПОСТЬ (32), ГРУСТНО (32), ДАВЛЕНИЕ (32), ДРОЖЬ (32), КАМЕНЕТЬ (32), КОРЧИТЬ (32), ЛАЗАРЕТ (32), МИЛИЦЕЙСКИЙ (32), НАЧАЛЬНИК (32), ЛИШЕНИЕ (32), ОДЕЖДА (32), ЛЕСОРУБ (32), ТРУДИТЬСЯ (32), СГОРЕТЬ (32), ПАМЯТНИК (32). Все слова имеют число 32.
Слово СИГАРЕТА (25) – ЧЕРТ (25), МУСОР (25), СЖЕЧЬ (25), ДЫМИТЬСЯ (25), КЛУБИТЬСЯ (25), КАШЕЛЬ (25), АГОНИЯ (25), ХОТЕТЬ (25), РАБСТВО (25), КРОВЬ (25), МОЗГ (25), КАРМАН (25), ДЕФИЦИТ(25), ДЕНЬГИ (25), БРОСИТЬ (25), ЖЕЛТЫЙ (25).
Слово ЛЮБОВНИЦА (35) даёт нам следующий маршрут со словами, имеющими число 35:
ЛЮБОВНИЦА (35) – ИСКУШЕНИЕ (35), ТЕЛЕФОН (35), АВТОМОБИЛЬ (35), РАЗДЕТЬ (35), РОМАНТИКА (35), ЗАРАЗИТЬ (35), ДОГАДАТЬСЯ (35), ПРОТЕСТ (35), ЗАРПЛАТА (35), ТРЕБОВАТЬ (35), УПРЕКАТЬ (35), ЗАПРЕТ (35), ПУБЛИЧНЫЙ (35), УПРЯМЫЙ (35), ХЛОПОТЫ (35), РАЗОЙТИСЬ (35), ХОЛОСТОЙ (35).
ЛЮБОВНИК (31) + ЛЮБОВНИЦА (35) = ПЕРВОПРИЧИНА (66)
МУЖЧИНА (31) + ЖЕНЩИНА (37) = КРОВОСМЕШЕНИЕ (68)
Вместе с тем есть и другой путь:
МУЖ (16) – БУКЕТ (16), СВАДЬБА (16), УСАДЬБА (16), УКЛАД (16), ПУТЬ (16).
ЖЕНА (21) – АНГЕЛ (21), ЧИСТОТА (21), ДАРИТЬ (21), ЛЮБИМЫЙ (21), СЕМЬЯ (21), РОД (21).
МУЖ (16) + ЖЕНА (21) = ВЕРНОСТЬ (37), ГНЕЗДО (37), ЦЕННОСТЬ (37), СОЗНАНИЕ (37).
Слово ИЗМЕНА (28) «дружит» со словами ДЬЯВОЛ (28), КРОВАТЬ (28), ЖРЕБИЙ (28), ХЛАМИДИЯ (28), МУЧИТЬСЯ (28), ЯДОВИТЫЙ (28), ЧЕРВЬ (28).
А когда вся нечисть собирается вместе, то получается:
БЕС (9) + САТАНА (12) + ДЬЯВОЛ (28) = ТРИХОМОНАДА (49), АМОРАЛЬНОСТЬ (49).
4+9=13 – РАК (13), СПИД (13), СВАЛКА (13).
Даже так называемые нецензурные, матерные слова точно также вписываются в данную систему Слово-Число. Например, известное матерное слово из 3-х букв, означающее мужской половой орган – Х..(10) + матерное слово, означающее женский половой орган П…(24) в сумме даёт число 34 РАЗВРАТ. А вот если говорить более литературным языком, то получается совсем другое понимание.
ФАЛОС (17) + ВАГИНА (16) = ТВОРЕЦ (33)
Русский язык, великий и могучий, всегда стоял и стоит на страже своего народа, страны. В нём запечатана, вложена, говоря современным языком – вмонтирована Божественная, Вселенская Истина.
После всего изложенного появляется мысль о том, что с помощью русского языка можно найти ответы на самые разные вопросы о жизни, семье, обществе, болезнях и др.
1 Специалисты насчитывают до десяти и более. (назад в текст)
2 Лексика – устанавливает значения слов, смысловые отношения между словами. (назад в текст)
3 Морфология – раздел грамматики изучающий слово в системе форм словоизмения. Предметом морфологии являются части речи и лексико-грамматические категории, находящие своё выражение в соответствующих системах форм. (назад в текст)
4 По этой же причине и психика у человека двухуровневая, соответственно и состояние – без сознания и в сознании. Великая дихотомия Вселенной. (назад в текст)
5 Врадуге цветов семь, красный цвет – первый. (назад в текст)